make a new branch for yourself + set it to track origin (upstream branch):
$ git checkout -b MyNameIsLocalBranch origin/working-on-remote-branch
Branch MyNameIsLocalBranch set up to track remote branch working-on-remote-branch from origin.
Switched to a new branch 'MyNameIsLocalBranch'
git all branches untangled
$ git remote show origin
* remote origin
Fetch URL: https://git.remote.tech/project/git-stuff.git
Push URL: https://git.remote.tech/project/git-stuff.git
HEAD branch: ns-head-branch
Remote branches:
site-one tracked
site-two tracked
best-branch tracked
working-on-remote-branch tracked
Local branch configured for 'git pull':
MyNameIsLocalBranch merges with remote working-on-remote-branch (if used: git checkout -b MyNameIsLocalBranch origin/working-on-remote-branch )
Local ref configured for 'git push':
MyNameIsLocalBranch pushes to remote working-on-remote-branch (up to date)
Didn’t set up origin branch originally?
Switch MyNameIsLocalBranch to track origin
switch to current local tracking branch (usually has same name as remote branch e.g. working-on-remote-branch and unset it.
$git branch --unset-upstream
switch to MyNameIsLocalBranch (git checkout MyNameIsLocalBranch)
$ git branch -u origin/working-on-remote-branch
Branch 'MyNameIsLocalBranch' set up to track remote branch 'working-on-remote-branch' from 'origin'.
check tracking:
$ git remote show origin
...
...
...
Local branch configured for 'git pull': MyNameIsLocalBranch merges with remote working-on-remote-branch
MyNameIsLocalBranch will not be PUSHING to remote/working-on-remote-branch – but we will set it up to in the push phase
How to Check Which Git Branches Are Tracking Which Upstream Branch
List all your branches and branch tracking by running git branch with the -vv option:
TO REMOTE pt1: STATUS see what you have changed – provides a list:
git status
TO REMOTE pt2: ADD add changes into git to be committed:
git add filenamefromstatuslist
(can do them one at a time or use git add .)
TO REMOTE pt3: COMMIT once you add them – commit them:
git commit -a -m “a note about what these changes are for”
TO REMOTE pt4: PULL get tip of remote even + integrate remote into local branch:
Different Named Branches Need Pulling
Pull performs a merge on the retrieved changes, you should ensure that your local work is committed before running the pull command.
Before you begin to push – you have a local branch with a different name (MyNameIsLocalBranch) than the remote (working-on-remote-branch):
In order to push your MyNameIsLocalBranch to another branch, you may need to merge the remote working-on-remote-branch branch to your current local branch MyNameIsLocalBranch.
In order to be merged, the tip of the remote branch cannot be behind the branch you are trying to push.
Before pushing, make sure to pull the changes from the remote branch and integrate them with your current local branch.
$ git pull origin working-on-remote-branch (will pull working-on-remote-branch from remote)
$ git checkout MyNameIsLocalBranch (to be sure you are on correct local branch)
$ git merge origin/working-on-remote-branch (merge remote into MyNameIsLocalBranch)
Merging changes into your local branch (more examples)
Merging combines your local changes with changes made by others.
Typically, you’d merge a remote-tracking branch (i.e., a branch fetched from a remote repository) with your local branch:
$ git merge remotename/branchname
# Merges updates made online with your local work
Pulling changes from a remote repository
git pull is a convenient shortcut for completing both git fetch and git merge in the same command:
$ git pull remotename branchname
# Grabs online updates and merges them with your local work
Because pull performs a merge on the retrieved changes, you should ensure that your local work is committed before running the pull command. If you run into a merge conflict you cannot resolve, or if you decide to quit the merge, you can use git merge –abort to take the branch back to where it was in before you pulled.
another merge example
merge is used to bring two (or more) branches together.
a little example:
# on branch A:
# create new branch B
$ git checkout -b B
# hack hack
$ git commit -am "commit on branch B"
# create new branch C from A
$ git checkout -b C A
# hack hack
$ git commit -am "commit on branch C"
# go back to branch A
$ git checkout A
# hack hack
$ git commit -am "commit on branch A"
so now there are three separate branches (namely A B and C) with different heads
to get the changes from B and C back to A, checkout A (already done in this example) and then use the merge command:
# create an octopus merge
$ git merge B C
your history will then look something like this:
…-o-o-x-------A
|\ /|
| B---/ |
\ /
C---/
if you want to merge across repository/computer borders, have a look at git pull command, e.g. from the pc with branch A (this example will create two new commits):
# pull branch B
$ git pull ssh://host/… B
# pull branch C
$ git pull ssh://host/… C
CONNECT:
sshfs user@ip.add.re.ss:/home3/usr/public_html/ ~/desktop/sshsf/bluehost
UNMOUNT:
diskutil umount /Users/spiffy/desktop/sshsf/bluehost
drag to trash / eject - unmount does not seem to work
The .git/config file in a particular clone of a repository is local to that clone. Any settings placed there will only affect actions for that particular project.
(By default, git config modifies .git/config, not ~/.gitconfig – only with –global does it modify the latter.)
In its default mode, git pull is shorthand for git fetch followed by git merge FETCH_HEAD.
When you do a git pull origin master, git pull performs a merge, which often creates a merge commit. Therefore, by default, pulling from the remote is NOT a harmless operation: it can create a new commit sha that didn’t exist before. This behavior can confuse a user, because what feels like it should be a harmless download operation actually changes the commit history in unpredictable ways.
To avoid this, you need
git pull --ff-only
(or not? read on to see which one fits your requirements)
With git pull --ff-only, Git will update your branch only if it can be “fast-forwarded” without creating new commits. If this can’t be done, git pull --ff-only simply aborts with an error message.
You can configure your Git client to always use --ff-only by default, so you get this behavior even if you forget the command-line flag:
git config --global pull.ff only
Note: The --global flag applies the change for all repositories on your machine. If you want this behaviour only for the repository you're in, omit the flag.
Pulling without specifying how to reconcile divergent branches is discouraged. You can squelch this message by running one of the following commands sometime before your next pull:
git config pull.rebase false # merge (the default strategy)
git config pull.rebase true # rebase
git config pull.ff only # fast-forward only
You can replace "git config" with "git config –global" to set a default preference for all repositories. You can also pass –rebase, –no-rebase, or –ff-only on the command line to override the configured default per invocation.
The warning presents three commands as options, all of these will suppress the warning. But they serve different purposes:
git config pull.rebase false # merge (the default strategy)
This keeps the default behaviour and suppresses the warning.
git config pull.rebase true # rebase
This actually commits on top of the remote branch, maintaining a single branch both locally and remotely (unlike the default behaviour where two different branches are involved – one on local and the other on remote – and, to combine the two, a merge is performed).
git config pull.ff only # fast-forward only
This only performs the pull if the local branch can be fast-forwarded. If not, it simply aborts with an error message (and does not create any commits).
Update:
If you have Git 2.29 or above, you can now set pull.ff to false, true or only to get rid of the warning.
git config pull.ff true
true – This is the default behaviour. Pull is fast-forwarded if possible, otherwise it's merged.
git config pull.ff false
false – Pull is never fast-forwarded, and a merge is always created.
git config pull.ff only
only – Pull is fast-forwarded if possible, otherwise operation is aborted with an error message.
To undo a Git commit that was not pushed, you are given a few major options:
Undo the commit but keep all changes staged
Undo the commit and unstage the changes
Undo the commit and lose all changes
Method 1: Undo commit and keep all files staged
In case you just want to undo the commit and change nothing more, you can use
git reset --soft HEAD~;
This is most often used to make a few changes to your latest commit and/or fix your commit message. Leaves working tree as it was before reset. soft does not touch the index file or the working tree at all (but resets the head to the previous commit). This leaves all your changed files Changes to be committed, as git status would put it.
Method 2: Undo commit and unstage all files
In case you want to undo the last commit and unstage all the files you can use the following
git reset HEAD~;
or
git reset --mixed HEAD~;
mixed will reset the index but not the working tree (i.e., the changed files are preserved but not marked for commit) and reports what has not been updated. This is the default action.
Method 3: Undo the commit and completely remove all changes
The following method will undo the commit and revert all changes so that your state is exactly as it was before you started making changes.
git reset --hard HEAD~;
hard resets the index and working tree. Any changes to tracked files in the working tree since the previous commit are discarded.
Note: In case you just want to rewrite the commit message, you could use git –amend instead.
If you're brand new to Git, you can learn how to start using Git on the command line. Now, without any further ado, here's how we can fix six of the most common Git mistakes.
1. Oops… I spelled that last commit message wrong
After a good few hours of coding, it's easy for a spelling error to sneak into your commit messages. Luckily, there's a simple fix.
git commit --amend
This will open up your editor and allow you to make a change to that last commit message. No one needs to know you spelled, "addded" with three "d"s.
2. Oops… I forgot to add a file to that last commit
Another common Git pitfall is committing too early. You missed a file, forgot to save it, or need to make a minor change for the last commit to make sense. --amend is your friend once again.
Add that missed file then run that trusty command.
git add missed-file.txt
git commit --amend
At this point, you can either amend the commit message or just save it to keep it the same.
3. Oops… I added a file I didn't want in the repo
But what if you do the exact opposite? What if you added a file that you didn't want to commit? A rogue ENV file, a build directory, a picture of your cat that you accidentally saved to the wrong folder? It's all fixable.
If all you did was stage the file and you haven't committed it yet, it's as simple as resetting that staged file:
git reset /assets/img/misty-and-pepper.jpg
If you've gone as far as committing that change, you need to run an extra step before:
This will undo the commit, remove the image, then add a new commit in its place.
4. Oops… I committed all those changes to the master branch
So you're working on a new feature and in your haste, you forgot to open a new branch for it. You've already committed a load of files and now them commits are all sitting on the master branch. Luckily, GitLab can prevent you from pushing directly to master. So we can roll back all these changes to a new branch with the following three commands:
Note: Make sure you commit or stash your changes first, or all will be lost!
This creates a new branch, then rolls back the master branch to where it was before you made changes, before finally checking out your new branch with all your previous changes intact.
5. Oops… I made a spelling mistake in my branch name
The keen-eyed among you will notice a slight spelling error in my last example. It's almost 3:00 PM and I haven't had lunch yet, so in my hunger, I've named our new branch future-brunch. Delicious.
We rename this branch in a similar way to how we rename a file with the mv command: by moving it to a new location with the correct name.
git branch -m future-brunch feature-branch
If you've already pushed this branch, there are a couple of extra steps required. We need to delete the old branch from the remote and push up the new one:
This command is for when everything has gone wrong. When you've copy-pasted one too many solutions from Stack Overflow and your repo is in a worse state than it was when you started. We've all been there.
git reflog shows you a list of all the things you've done. It then allows you to use Git's magical time-traveling skills to go back to any point in the past. I should note, this is a last resort thing and should not be used lightly. To get this list, type:
git reflog
Every step we took, every move we made, Git was watching us. Running that on our project gives us this:
3ff8691 (HEAD -> feature-branch) HEAD@{0}: Branch: renamed refs/heads/future-brunch to refs/heads/feature-branch
3ff8691 (HEAD -> feature-branch) HEAD@{2}: checkout: moving from master to future-brunch
2b7e508 (master) HEAD@{3}: reset: moving to HEAD~
3ff8691 (HEAD -> feature-branch) HEAD@{4}: commit: Adds the client logo
2b7e508 (master) HEAD@{5}: reset: moving to HEAD~1
37a632d HEAD@{6}: commit: Adds the client logo to the project
2b7e508 (master) HEAD@{7}: reset: moving to HEAD
2b7e508 (master) HEAD@{8}: commit (amend): Added contributing info to the site
dfa27a2 HEAD@{9}: reset: moving to HEAD
dfa27a2 HEAD@{10}: commit (amend): Added contributing info to the site
700d0b5 HEAD@{11}: commit: Addded contributing info to the site
efba795 HEAD@{12}: commit (initial): Initial commit
Take note of the left-most column, as this is the index. If you want to go back to any point in the history, run the below command, replacing {index} with that reference, e.g. dfa27a2.
git reset HEAD@{index}
So there you have six ways to get out of the most common Gitfalls.
Depending on your version control system, conflicts may arise in different situations.
When you work in a team, you may come across a situation when somebody commits changes to a file you are currently working on. If these changes do not overlap (that is, changes were made to different lines of code), the conflicting files are merged automatically. However, if the same lines were affected, your version control system cannot randomly pick one side over the other, and asks you to resolve the conflict.
Conflicts may also arise when merging, rebasing or cherry-picking branches.
Non-Distributed Version Control Systems
When you try to edit a file that has a newer version on the server, IntelliJ IDEA informs you about that, showing a message popup in the editor:
In this case, you should update your local version before changing the file, or merge changes later.
If you attempt to commit a file that has a newer repository version, the commit fails, and an error is displayed in the bottom right corner telling you that the file you are trying to commit is out of date.
If you synchronize a file that already has local changes with a newer repository version committed by somebody else, a conflict occurs. The conflicting file gets the Merged with conflicts status. The file remains in the same changelist in the Local Changes view, but its name is highlighted in red. If the file is currently opened in the editor, the filename on the tab header is also highlighted in red.
Distributed Version Control Systems
Under distributed version control systems, such as Git and Mercurial, conflicts arise when a file you have committed locally has changes to the same lines of code as the latest upstream version and when you attempt to perform one of the following operations: pull, merge, rebase, cherry-pick, unstash, or apply patch.
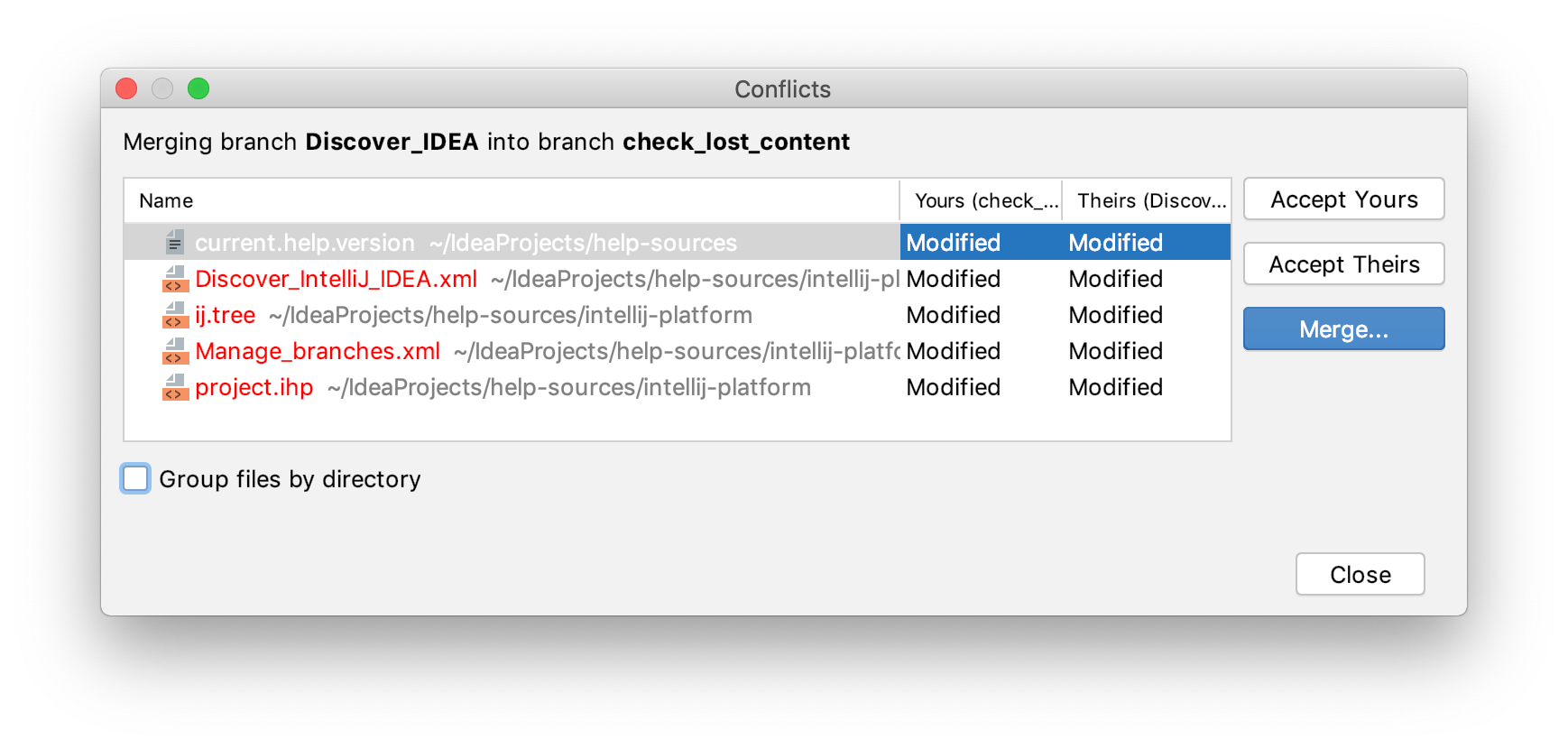
If there are conflicts, these operations will fail and you will be prompted to accept the upstream version, prefer your version, or merge the changes manually:
The Conflicts dialog is triggered automatically when a conflict is detected on the Version Control level.
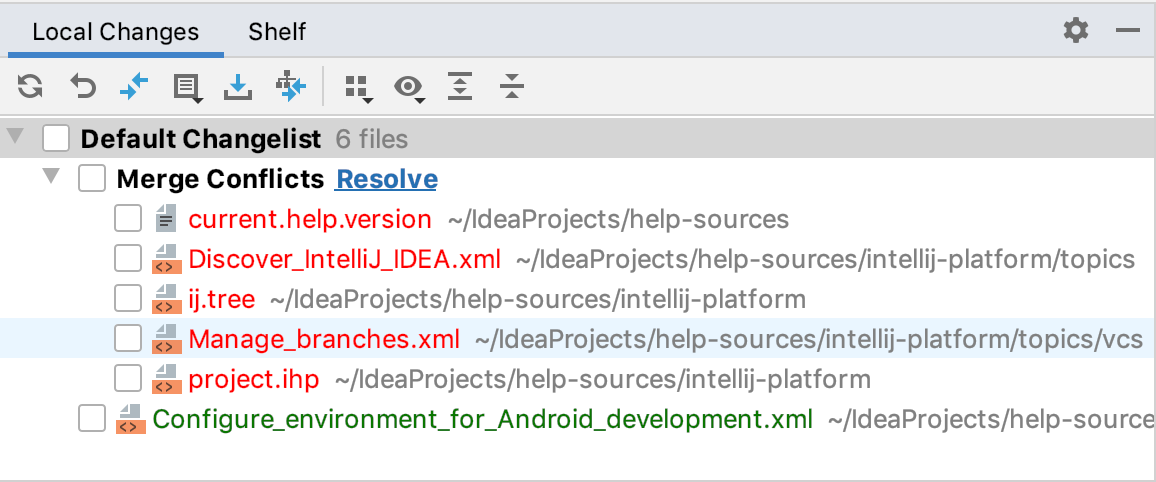
If you click Close in this dialog, or call a Git operation that leads to a merge conflict from command line, a Merge Conflicts node will appear in the Local Changes view with a link to resolve them:
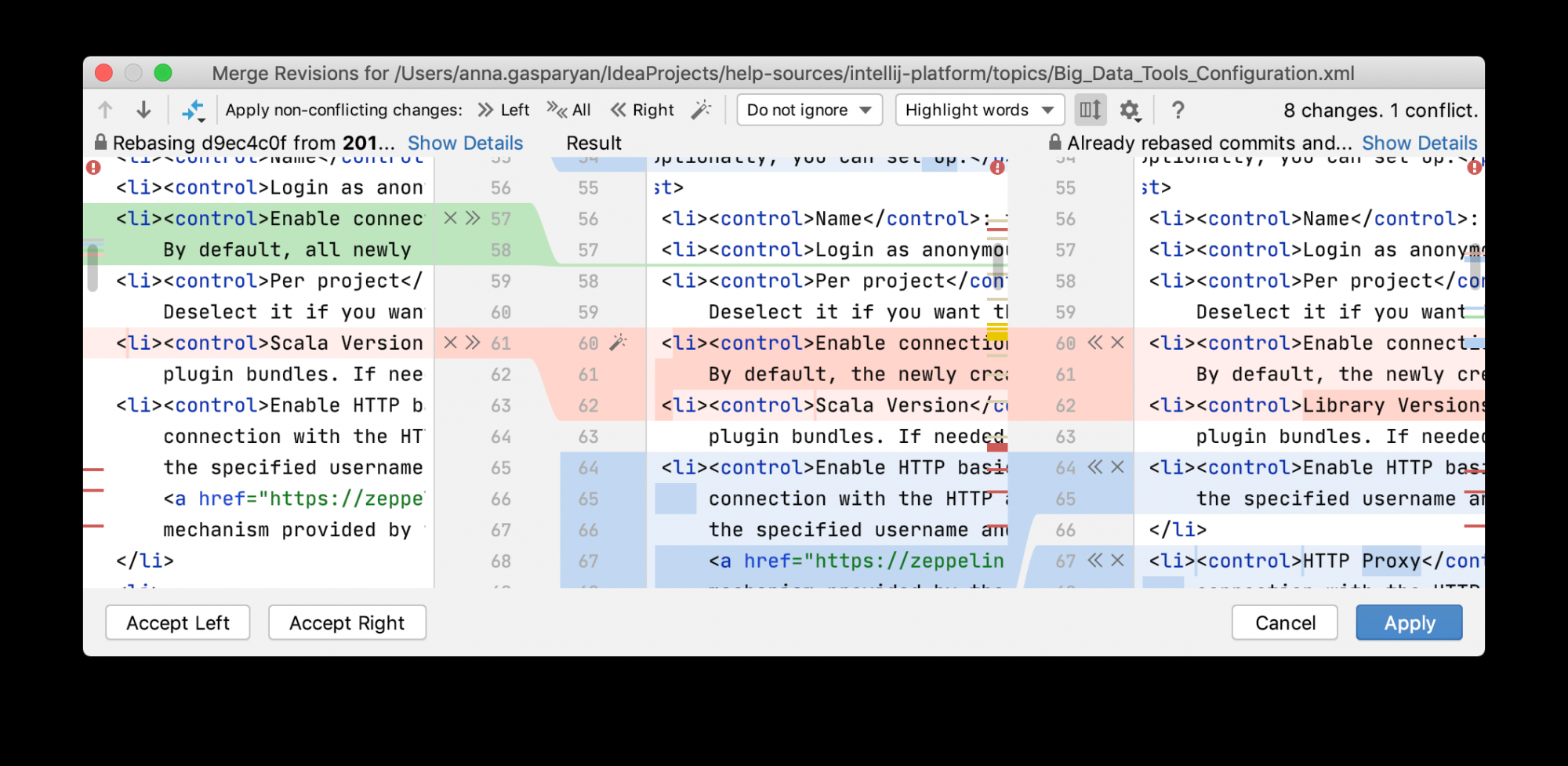
IntelliJ IDEA provides a tool for resolving conflicts locally. This tool consists of three panes:
The left page shows the read-only local copy
The right pane shows the read-only version checked in to the repository
The central pane shows a fully-functional editor where the results of merging and conflict resolving are displayed. Initially, the contents of this pane is the same as the base revision of the file, that is, the revision from which both conflicting versions are derived.
Resolve conflicts
Last modified: 08 March 2021
When you work in a team, you may come across a situation when somebody pushes changes to a file you are currently working on. If these changes do not overlap (that is, changes were made to different lines of code), the conflicting files are merged automatically. However, if the same lines were affected, Git cannot randomly pick one side over the other, and asks you to resolve the conflict.
In Git, conflicts may arise when you attempt to perform one of the following operations: pull, merge, rebase, cherry-pick, unstash changes or apply a patch. If there are conflicts, these operations will fail, and you will be prompted to accept the upstream version, prefer your version, or merge the changes:
The Conflicts dialog is triggered automatically when a conflict is detected on the Git level.
If you click Close in this dialog, or call a Git operation that leads to a merge conflict from command line, a Merge Conflicts node will appear in the Local Changes view with a link to resolve them:
IntelliJ IDEA provides a tool for resolving conflicts locally. This tool consists of three panes:
The left pane shows the read-only local copy
The right pane shows the read-only version checked in to the repository.
The central pane is a fully-functional editor where the results of resolving conflicts are displayed. Initially, the contents of this pane are the same as the base revision of the file, that is, the revision from which both conflicting versions are derived.
Resolve conflicts
Click Merge in the Conflicts dialog, the Resolve link in the Local Changes view, or select the conflicting file in the editor and choose VCS | Git | Resolve Conflicts from the main menu.
To automatically merge all non-conflicting changes, click (Apply All Non-Conflicting Changes) on the toolbar. You can also use the (Apply Non-Conflicting Changes from the Left Side) and (Apply Non-Conflicting Changes from the Right Side) to merge non-conflicting changes from the left/right parts of the dialog respectively.
To resolve a conflict, you need to select which action to apply (accept or ignore ) to the left (local) and the right (repository) version, and check the resulting code in the central pane:
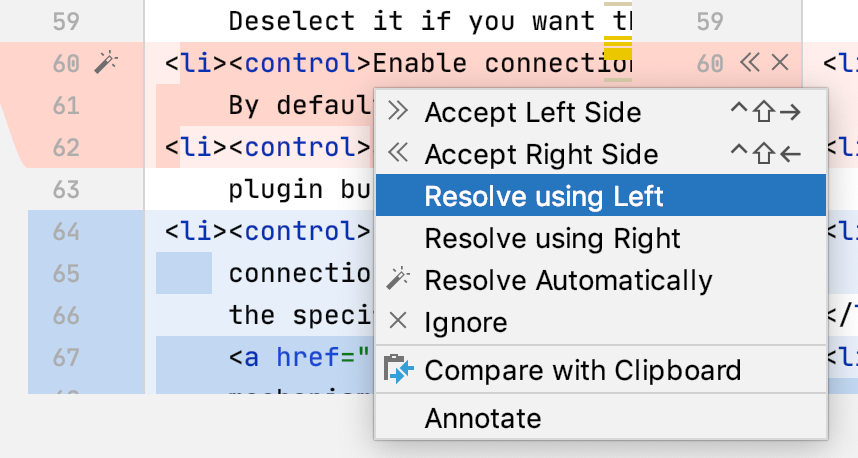
You can also right-click a highlighted conflict in the central pane and use the commands from the context menu. The Resolve using Left and Resolve using Right commands provide a shortcut to accepting changes from one side and ignoring them from the other side respectively:
For simple conflicts (for example, if the beginning and the end of the same line have been modified in different file revisions), the Resolve simple conflicts button that allows merging the changes in one click becomes available.
Such conflicts are not resolved with the Apply All Non-Conflicting Changes action since you must make sure that they are resolved properly.
Note that the central pane is a fully-functional editor, so you can make changes to the resulting code directly in this dialog.
It may also be useful to compare different versions to resolve a conflict. Use the toolbar button to invoke the list of options. Note that Base refers to the file version that the local and the repository versions originated from (initially displayed in the middle pane), while Middle refers to the resulting version.
Review merge results in the central pane and click Apply.
Productivity tips
Apply non-conflicting changes automatically
You can configure IntelliJ IDEA to always apply non-conflicting changes automatically instead of telling it to do so from the Merge dialog. To do this, select the Automatically apply non-conflicting changes option on the Tools | Diff Merge page of the IDE settings ⌘,.
Manage changes in the central pane
You can manage changes in the central pane using the toolbar that appears when you hover the mouse cursor over a change marker in the gutter, and then click it. The toolbar is displayed together with a frame showing the previous contents of the modified line:For example, when there are multiple non-conflicting changes, and you only need to skip one or two of them, it's easier to apply all of them simultaneously using the Apply all non-conflicting changes action, and then undo the unwanted ones using the Revert action from this toolbar.
Handle conflicts related to LF and CRLF line endings
Quite often, people working in a team and contributing to the same repository use different operating systems. This may result in problems with line ending, because Unix, Linux and MacOS us LF, and Windows uses CRLF to mark the end of a line.
IntelliJ IDEA displays the discrepancies in line endings in the Differences Viewer, so you can fix them manually. If you want Git to solve such conflicts automatically, you need to set the core.autocrlf attribute to true on Windows and to input on Linux and MacOS (for more details, see Dealing with line endings). You can change the configuration manually by running git config --global core.autocrlf true on Windows or git config --global core.autocrlf input on Linux and macOS.
However, IntelliJ IDEA can automatically analyze your configuration, warn you if you are about to commit CRLF into a remote repository, and suggest setting the core.autocrlf setting to true or input depending on your operating system.
To enable smart handling of LF and CRLF line separators, open the Settings/Preferences dialog ⌘,, and select the Version Control | Git node on the left. Enable the Warn if CRLF line separators are about to be committed option.
After you have enabled this option, IntelliJ IDEA will display the Line Separators Warning Dialog each time you are about to commit a file with CRLF separators, unless you have set any related Git attributes in the affected file (in this case, IntelliJ IDEA supposes that you clearly understand what you are doing and excludes this file from analysis).
In the Line Separators Warning Dialog, click one of the following:
Commit As Is to ignore the warning and commit a file with CRFL separators.
Fix and Commit to have the core.autocrlf attribute set to true or input depending on your operating system. As a result, CRLF line separators will be replaced with LF before the commit.
If, at a later time, you need to review how exactly conflicts were resolved during a merge, you can locate the required merge commit in the Log tab of the Git tool window ⌘9, select a file with conflicts in the Commit Details pane in the right, and click < or press ⌘D (see Review how changes were merged for details).
NPM creates a new package-lock.json – do you commits?
(e.g. my version of silvermine player had to be updated to match up with the updated package.json file from stage)
Yes, package-lock.json is intended to be checked into source control. If you're using npm 5+, you may see this notice on the command line: created a lockfile as package-lock.json. You should commit this file. According to npm help package-lock.json:
package-lock.json is automatically generated for any operations where npm modifies either the node_modules tree, or package.json. It describes the exact tree that was generated, such that subsequent installs are able to generate identical trees, regardless of intermediate dependency updates.
This file is intended to be committed into source repositories, and serves various purposes:
Describe a single representation of a dependency tree such that teammates, deployments, and continuous integration are guaranteed to install exactly the same dependencies.
Provide a facility for users to "time-travel" to previous states of node_modules without having to commit the directory itself.
To facilitate greater visibility of tree changes through readable source control diffs.
And optimize the installation process by allowing npm to skip repeated metadata resolutions for previously-installed packages.
One key detail about package-lock.json is that it cannot be published, and it will be ignored if found in any place other than the toplevel package. It shares a format with npm-shrinkwrap.json, which is essentially the same file, but allows publication. This is not recommended unless deploying a CLI tool or otherwise using the publication process for producing production packages.
If both package-lock.json and npm-shrinkwrap.json are present in the root of a package, package-lock.json will be completely ignored.
If software did not resolve package.json conflicts
Occasionally, two separate npm install will create package locks that cause merge conflicts in source control systems. As of npm@5.7.0, these conflicts can be resolved by manually fixing any package.json conflicts, and then running npm install [--package-lock-only] again. npm will automatically resolve any conflicts for you and write a merged package lock that includes all the dependencies from both branches in a reasonable tree. If --package-lock-only is provided, it will do this without also modifying your local node_modules/.
To make this process seamless on git, consider installing npm-merge-driver, which will teach git how to do this itself without any user interaction. In short: $ npx npm-merge-driver install -g will let you do this, and even works with pre-npm@5.7.0 versions of npm 5, albeit a bit more noisily. Note that if package.json itself conflicts, you will have to resolve that by hand and run npm install manually, even with the merge driver.
Conceptually, the "input" to npm install is a package.json, while its "output" is a fully-formed node_modules tree: a representation of the dependencies you declared. In an ideal world, npm would work like a pure function: the same package.json should produce the exact same node_modules tree, any time. In some cases, this is indeed true. But in many others, npm is unable to do this. There are multiple reasons for this:
different versions of npm (or other package managers) may have been used to install a package, each using slightly different installation algorithms.
a new version of a direct semver-range package may have been published since the last time your packages were installed, and thus a newer version will be used.
A dependency of one of your dependencies may have published a new version, which will update even if you used pinned dependency specifiers (1.2.3 instead of ^1.2.3)
The registry you installed from is no longer available, or allows mutation of versions (unlike the primary npm registry), and a different version of a package exists under the same version number now.
If these are the only versions of A, B, and C available in the registry, then a normal npm install A will install:
A@0.1.0
`-- B@0.0.1
`-- C@0.0.1
However, if B@0.0.2 is published, then a fresh npm install A will install:
A@0.1.0
`-- B@0.0.2
`-- C@0.0.1
assuming the new version did not modify B's dependencies. Of course, the new version of B could include a new version of C and any number of new dependencies. If such changes are undesirable, the author of A could specify a dependency on B@0.0.1. However, if A's author and B's author are not the same person, there's no way for A's author to say that he or she does not want to pull in newly published versions of C when B hasn't changed at all.
To prevent this potential issue, npm uses package-lock.json or, if present, npm-shrinkwrap.json. These files are called package locks, or lockfiles.
Whenever you run npm install, npm generates or updates your package lock, which will look something like this:
This file describes an exact, and more importantly reproduciblenode_modules tree. Once it's present, any future installation will base its work off this file, instead of recalculating dependency versions off package.json.
The presence of a package lock changes the installation behavior such that:
The module tree described by the package lock is reproduced. This means reproducing the structure described in the file, using the specific files referenced in "resolved" if available, falling back to normal package resolution using "version" if one isn't.
The tree is walked and any missing dependencies are installed in the usual fashion.
If preshrinkwrap, shrinkwrap or postshrinkwrap are in the scripts property of the package.json, they will be executed in order. preshrinkwrap and shrinkwrap are executed before the shrinkwrap, postshrinkwrap is executed afterwards. These scripts run for both package-lock.json and npm-shrinkwrap.json. For example to run some postprocessing on the generated file:
Using a locked package is no different than using any package without a package lock: any commands that update node_modules and/or package.json's dependencies will automatically sync the existing lockfile. This includes npm install, npm rm, npm update, etc. To prevent this update from happening, you can use the --no-save option to prevent saving altogether, or --no-shrinkwrap to allow package.json to be updated while leaving package-lock.json or npm-shrinkwrap.json intact.
It is highly recommended you commit the generated package lock to source control: this will allow anyone else on your team, your deployments, your CI/continuous integration, and anyone else who runs npm install in your package source to get the exact same dependency tree that you were developing on. Additionally, the diffs from these changes are human-readable and will inform you of any changes npm has made to your node_modules, so you can notice if any transitive dependencies were updated, hoisted, etc.
Resolving lockfile conflicts
Occasionally, two separate npm install will create package locks that cause merge conflicts in source control systems. As of npm@5.7.0, these conflicts can be resolved by manually fixing any package.json conflicts, and then running npm install [--package-lock-only] again. npm will automatically resolve any conflicts for you and write a merged package lock that includes all the dependencies from both branches in a reasonable tree. If --package-lock-only is provided, it will do this without also modifying your local node_modules/.
To make this process seamless on git, consider installing npm-merge-driver, which will teach git how to do this itself without any user interaction. In short: $ npx npm-merge-driver install -g will let you do this, and even works with pre-npm@5.7.0 versions of npm 5, albeit a bit more noisily. Note that if package.json itself conflicts, you will have to resolve that by hand and run npm install manually, even with the merge driver.
DO NOT – Delete `package-lock.json` to Resolve Conflicts quickly
Yes it can have bad side effects, maybe not very often but for example you can have in package.json “moduleX”: “^1.0.0” and you used to have “moduleX”: “1.0.0” in package-lock.json.
By deleting package-lock.json and running npm install you could be updating to version 1.0.999 of moduleX without knowing about it and maybe they have created a bug or done a backwards breaking change (not following semantic versioning).
Anyway there is already a standard solution for it.
Fix the conflict inside package.json
Run: npm install –package-lock-only
https://docs.npmjs.com/cli/v7/configuring-npm/package-locks#resolving-lockfile-conflicts
package-lock.json – role
It stores an exact, versioned dependency tree rather than using starred versioning like package.json itself (e.g. 1.0.*). This means you can guarantee the dependencies for other developers or prod releases, etc. It also has a mechanism to lock the tree but generally will regenerate if package.json changes.
package-lock.json is automatically generated for any operations where npm modifies either the node_modules tree, or package.json. It describes the exact tree that was generated, such that subsequent installs are able to generate identical trees, regardless of intermediate dependency updates.
This file is intended to be committed into source repositories, and serves various purposes:
Describe a single representation of a dependency tree such that teammates, deployments, and continuous integration are guaranteed to install exactly the same dependencies.
Provide a facility for users to “time-travel” to previous states of node_modules without having to commit the directory itself.
To facilitate greater visibility of tree changes through readable source control diffs.
And optimize the installation process by allowing npm to skip repeated metadata resolutions for previously-installed packages.”
To answer jrahhali’s question below about just using the package.json with exact version numbers. Bear in mind that your package.json contains only your direct dependencies, not the dependencies of your dependencies (sometimes called nested dependencies). This means with the standard package.json you can’t control the versions of those nested dependencies, referencing them directly or as peer dependencies won’t help as you also don’t control the version tolerance that your direct dependencies define for these nested dependencies.
Even if you lock down the versions of your direct dependencies you cannot 100% guarantee that your full dependency tree will be identical every time. Secondly you might want to allow non-breaking changes (based on semantic versioning) of your direct dependencies which gives you even less control of nested dependencies plus you again can’t guarantee that your direct dependencies won’t at some point break semantic versioning rules themselves.
The solution to all this is the lock file which as described above locks in the versions of the full dependency tree. This allows you to guarantee your dependency tree for other developers or for releases whilst still allowing testing of new dependency versions (direct or indirect) using your standard package.json.
NB. The previous shrink wrap json did pretty much the same thing but the lock file renames it so that it’s function is clearer. If there’s already a shrink wrap file in the project then this will be used instead of any lock file.
One thing that can be costly when done wrong is solving conflicts in generated files, like package-lock.json. It usually happens when two branches add or update a dependency. The result of package-lock then changes, and whoever gets their PR merged to main first is the lucky one who avoided those conflicts. It's almost like a race.
So here you are, updating your PR with the base branch, and git shows you this huge amount of conflicts in package-lock.json. The conflicts in package.json are usually easily solved (if there even are any), so I think it is tempting to just delete package-lock.json and run npm install. After all, this will give you a brand new package-lock.json, which you can happily commit.
Why you should never delete package-lock.json
When you install a dependency for the first time, it is usually automatically added to your dependencies or devDependencies with ^version, which means "compatible with version, according to semver". You can try out what that means here.
Enter, for example, lodash as the package and ^4.2.1 as version, and you will see that you can get anything from 4.2.1 to 4.17.20 (the latest version)
This is where package-lock.json comes into play. Upon installing, it will "lock" you in on the version that you just installed. So if 4.2.1 is the latest version at the moment of your install, this version will be written to package-lock and will, from there on, always be installed. Even if newer versions come out that are theoretically compatible with it.
This is important because it guarantees that every developer in the team will have the same version on their machine, and it is equally important for CI/CD. I would not want to ship a newer version to production than we tested with, even if it's just a patch version.
So when you delete package-lock.json, all those consistency goes out the window. Every node_module you depend on will be updated to the latest version it is theoretically compatible with. This means no major changes, but minors and patches. I believe this is bad for three reasons:
It trusts that everyone strictly adheres to semantic versioning, and I sincerely doubt that this is the case. There is also no way to enforce this.
Major version zero is exempt from the rules of semantic versioning. From
the semver spec
:
Major version zero (0.y.z) is for initial development. Anything MAY change at any time. The public API SHOULD NOT be considered stable.
Have a look at your package-lock.json and count how many dependencies with major version 0 you have. For this blog (made with gatsby) I have 362!
This also applies to transitive dependencies. So even if you are using strict versions (without the ^), the libraries you are using do not.
If you delete package-lock.json now from any one of your projects and run npm install again, it will most certainly look completely different.
Will your app be fine? Maybe, maybe not. No one can tell. For me, this would usually mean: "regression test everything", which is certainly not what I have in mind when I am just solving a conflict.
What you can do instead
My usual approach was the following:
Solve the conflicts in package.json
Take package-lock.json from the base branch
run npm install again
This will then just re-install whatever changes we made in our branch. However, I recently learned about and even easier way:
npm can automatically detect conflicts in package-lock.json and resolve them for us. From the npm docs:
Occasionally, two separate npm install will create package locks that cause merge conflicts in source control systems. As of npm@5.7.0, these conflicts can be resolved by manually fixing any package.json conflicts, and then running npm install [–package-lock-only] again. npm will automatically resolve any conflicts for you and write a merged package lock that includes all the dependencies from both branches in a reasonable tree. If –package-lock-only is provided, it will do this without also modifying your local node_modules/.
This means that we can just keep the conflicts in the lock file. All we have to do is get package.json right, and npm will do the rest for us 🎉.
I wish I had known this sooner – it would've saved me some trouble.
Other ways to unset remote tracking
You don’t have to delete your local branch.
Simply delete the local branch that is tracking the remote branch:
git branch -d -r origin/
-r, –remotes tells git to delete the remote-tracking branch (i.e., delete the branch set to track the remote branch). This will not delete the branch on the remote repo!
See “Having a hard time understanding git-fetch”
https://stackoverflow.com/questions/1070496/having-a-hard-time-understanding-git-fetch
there’s no such concept of local tracking branches, only remote tracking branches.
So origin/master is a remote tracking branch for master in the origin repo
As mentioned in Dobes Vandermeer’s answer, you also need to reset the configuration associated to the local branch:
git config --unset branch..remote
git config --unset branch..merge
Remove the upstream information for .
If no branch is specified it defaults to the current branch.
That will make any push/pull completely unaware of origin/.
Set tracking branches for existing local branches
On the other hand, you may have chosen to work on a local branch and to set the upstream branch (or the remote tracking branch later on).
It is perfectly fine, but you will have to use the “git branch” in order to set the existing branch upstream branch.
$ git branch -u /
Let’s take the example of the “feature” branch that you just created to start working.
$ git checkout -b feature
Switched to a new branch ‘feature’
You created some commits in your branch, you want to set the tracking branch to be master.
$ git branch -u origin/master
Branch ‘feature’ set up to track remote branch ‘master’ from ‘origin’.
Great! You successfully set the upstream branch for your existing local branch.
Sorting out which branch is which – origin / pull / push
“origin” is not special
Just like the branch name “master” does not have any special meaning in Git, neither does “origin”. While “master” is the default name for a starting branch when you run git init which is the only reason it’s widely used, “origin” is the default name for a remote when you run git clone. If you run git clone -o booyah instead, then you will have booyah/master as your default remote branch.
Using the example of my copy of Puppet checked out from the upstream Git repository on Github.com…
$ git remote show origin
* remote origin
Fetch URL: git://github.com/reductivelabs/puppet.git
Push URL: git://github.com/reductivelabs/puppet.git
HEAD branch: master
Remote branches:
0.24.x tracked
0.25.x tracked
2.6.x tracked
master tracked
next tracked
primordial-ooze tracked
reins-on-a-horse tracked
testing tracked
testing-17-march tracked
testing-18-march tracked
testing-2-april tracked
testing-2-april-midday tracked
testing-20-march tracked
testing-21-march tracked
testing-24-march tracked
testing-26-march tracked
testing-29-march tracked
testing-31-march tracked
testing-5-april tracked
testing-9-april tracked
testing4268 tracked
Local branch configured for 'git pull':
master merges with remote master
Local ref configured for 'git push':
master pushes to master (up to date)
Then if I were to execute the following:
$ git checkout -b local_2.6 -t origin/2.6.x
Branch local_2.6 set up to track remote branch 2.6.x from origin.
Switched to a new branch 'local_2.6'
And finally re-run the git remote show origin command again I will then see the following down near the bottom:
Local branches configured for 'git pull':
local_2.6 merges with remote 2.6.x
master merges with remote master
Upstream shorthand
When you have a tracking branch set up, you can reference its upstream branch with the @{upstream} or @{u} shorthand. So if you’re on the master branch and it’s tracking origin/master, you can say something like git merge @{u} instead of git merge origin/master if you wish.
Tracking Branches
Checking out a local branch from a remote-tracking branch automatically creates what is called a “tracking branch” (and the branch it tracks is called an “upstream branch”). Tracking branches are local branches that have a direct relationship to a remote branch. If you’re on a tracking branch and type git pull, Git automatically knows which server to fetch from and which branch to merge in.
When you clone a repository, it generally automatically creates a master branch that tracks origin/master. However, you can set up other tracking branches if you wish — ones that track branches on other remotes, or don’t track the master branch. The simple case is the example you just saw, running git checkout -b /. This is a common enough operation that Git provides the –track shorthand:
$ git checkout --track origin/serverfix
Branch serverfix set up to track remote branch serverfix from origin.
Switched to a new branch 'serverfix'
In fact, this is so common that there’s even a shortcut for that shortcut. If the branch name you’re trying to checkout (a) doesn’t exist and (b) exactly matches a name on only one remote, Git will create a tracking branch for you:
$ git checkout serverfix
Branch serverfix set up to track remote branch serverfix from origin.
Switched to a new branch 'serverfix'
To set up a local branch with a different name than the remote branch, you can easily use the first version with a different local branch name:
$ git checkout -b sf origin/serverfix
Branch sf set up to track remote branch serverfix from origin.
Switched to a new branch 'sf'
Now, your local branch sf will automatically pull from origin/serverfix.
If you already have a local branch and want to set it to a remote branch you just pulled down, or want to change the upstream branch you’re tracking, you can use the -u or –set-upstream-to option to git branch to explicitly set it at any time.
$ git branch -u origin/serverfix
Branch serverfix set up to track remote branch serverfix from origin.
Note
Upstream shorthand
When you have a tracking branch set up, you can reference its upstream branch with the @{upstream} or @{u} shorthand. So if you’re on the master branch and it’s tracking origin/master, you can say something like git merge @{u} instead of git merge origin/master if you wish.
If you want to see what tracking branches you have set up, you can use the -vv option to git branch. This will list out your local branches with more information including what each branch is tracking and if your local branch is ahead, behind or both.
$ git branch -vv
iss53 7e424c3 [origin/iss53: ahead 2] Add forgotten brackets
master 1ae2a45 [origin/master] Deploy index fix
* serverfix f8674d9 [teamone/server-fix-good: ahead 3, behind 1] This should do it
testing 5ea463a Try something new
So here we can see that our iss53 branch is tracking origin/iss53 and is “ahead” by two, meaning that we have two commits locally that are not pushed to the server. We can also see that our master branch is tracking origin/master and is up to date. Next we can see that our serverfix branch is tracking the server-fix-good branch on our teamone server and is ahead by three and behind by one, meaning that there is one commit on the server we haven’t merged in yet and three commits locally that we haven’t pushed. Finally we can see that our testing branch is not tracking any remote branch.
It’s important to note that these numbers are only since the last time you fetched from each server. This command does not reach out to the servers, it’s telling you about what it has cached from these servers locally. If you want totally up to date ahead and behind numbers, you’ll need to fetch from all your remotes right before running this. You could do that like this:
$ git fetch --all; git branch -vv
Pulling
While the git fetch command will fetch all the changes on the server that you don’t have yet, it will not modify your working directory at all. It will simply get the data for you and let you merge it yourself. However, there is a command called git pull which is essentially a git fetch immediately followed by a git merge in most cases. If you have a tracking branch set up as demonstrated in the last section, either by explicitly setting it or by having it created for you by the clone or checkout commands, git pull will look up what server and branch your current branch is tracking, fetch from that server and then try to merge in that remote branch.
Generally it’s better to simply use the fetch and merge commands explicitly as the magic of git pull can often be confusing.
Push Branch to Another Branch (different named branches)
In some cases, you may want to push your changes to another branch on the remote repository.
In order to push your branch to another branch, you may need to merge the remote branch to your current local branch.
In order to be merged, the tip of the remote branch cannot be behind the branch you are trying to push.
Before pushing, make sure to pull the changes from the remote branch and integrate them with your current local branch.
Note : when merging the remote branch, you are merging your local branch with the upstream branch of your local repository.
In order to push your branch to another remote branch, use the “git push” command and specify the remote name, the name of your local branch as the name of the remote branch.
$ git push <remote> <local_branch>:<remote_name>
As an example, let’s say that you have created a local branch named “my-feature”.
$ git branch
master
* my-feature
feature
However, you want to push your changes to the remote branch named “feature” on your repository.
In order to push your branch to the “feature” branch, you would execute the following command
$ git push origin my-feature:feature
Enumerating objects: 6, done.
Counting objects: 100% (6/6), done.
Delta compression using up to 2 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 513 bytes | 513.00 KiB/s, done.
Total 3 (delta 1), reused 0 (delta 0)
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
To https://github.com/SCHKN/repo.git
b1c4c91..9ae0aa6 my-feature -> feature
Origin
setting origin for local branch (different named branches)
Use the colon notation:
git push -u origin local_branch:remote_branch
More Origin notes
git remote show origin
origin is an aliason your system for a particular remote repository. It's not actually a property of that repository.
By doing
git push origin branchname
you're saying to push to the origin repository. There's no requirement to name the remote repository origin: in fact the same repository could have a different alias for another developer.
Remotes are simply an alias that store the URL of repositories. You can see what URL belongs to each remote by using
git remote -v
In the push command, you can use remotes or you can simply use a URL directly. An example that uses the URL:
git push git@github.com:git/git.git master
You can also specify -v, which shows you the URLs that Git has stored for the shortname to be used when reading and writing to that remote:
$ git remote -v
Set upstream branch – same name
Given a branch foo and a remote upstream:
As of Git 1.8.0:
git branch -u upstream/foo
Or, if local branch foo is not the current branch:
git branch -u upstream/foo foo
Or, if you like to type longer commands, these are equivalent to the above two:
All of the above commands will cause local branch foo to track remote branch foo from remote upstream.
The old (1.7.x) syntax is deprecated in favor of the new (1.8+) syntax. The new syntax is intended to be more intuitive and easier to remember.
Defining an upstream branch will fail when run against newly-created remotes that have not already been fetched. In that case, run git fetch upstream beforehand.
git branch --set-upstream-to, which can be used as follows, if you're on the branch my_branch:
It was tempting to say git branch --set-upstream origin/master, but that tells Git to arrange the local branch origin/master to integrate with the currently checked out branch, which is highly unlikely what the user meant. The option is deprecated; use the new --set-upstream-to (with a short-and-sweet -u) option instead.
A shortcut, which doesn't depend on remembering the syntax for git branch --set-upstream 1 is to do:
git push -u origin my_branch
… the first time that you push that branch. Or, to push to the current branch to a branch of the same name (handy for an alias):
git push -u origin HEAD
You only need to use -u once, and that sets up the association between your branch and the one at origin in the same way as git branch --set-upstream does.
Personally, I think it's a good thing to have to set up that association between your branch and one on the remote explicitly. It's just a shame that the rules are different for git push and git pull.
1 It may sound silly, but I very frequently forget to specify the current branch, assuming that's the default – it's not, and the results are most confusing
Update 2012-10-11: Apparently I'm not the only person who found it easy to get wrong! Thanks to VonC for pointing out that git 1.8.0 introduces the more obvious git branch --set-upstream-to, which can be used as follows, if you're on the branch my_branch:
It was tempting to say git branch --set-upstream origin/master, but that tells Git to arrange the local branch origin/master to integrate with the currently checked out branch, which is highly unlikely what the user meant. The option is deprecated; use the new --set-upstream-to (with a short-and-sweet -u) option instead.
When you're publishing a local branch – same names remote and local
Let's now look at the opposite scenario: you started a new local branch and now want to publish it on the remote for the first time:
$ git push -u origin dev
You can tell Git to track the newly created remote branch simply by using the -u flag with "git push".
When you decide at a later point in time
In cases when you simply forgot, you can set (or change) a tracking relationship for your current HEAD branch at any time:
$ git branch -u origin/dev
Push Branch To Remote – same names remote and local
In order to push a Git branch to remote, you need to execute the “git push” command and specify the remote as well as the branch name to be pushed.
$ git push <remote> <branch>
For example, if you need to push a branch named “feature” to the “origin” remote, you would execute the following query
$ git push origin feature
git push branch to remote
If you are not already on the branch that you want to push, you can execute the “git checkout” command to switch to your branch.
If your upstream branch is not already created, you will need to create it by running the “git push” command with the “-u” option for upstream.
git push upstream branch to remote
$ git push -u origin feature
Congratulations, you have successfully pushed your branch to your remote!












{kind=link}
{kind=link}